The idea with greatest impact in Word2Vec1 2 was that vector representations could capture linguistic regularities, which can be retrieved through vector arithmetics
vec('Rome') ≈ vec('Paris') - vec('France') + vec('Italy')
vec('Queen') ≈ vec('King') - vec('Man') + vec('Woman')
Awesome ! How could such results be achieved ? They came from the following assumption
The meaning of a word can be inferred by the company it keeps
Indeed, Word2Vec was built using unsupervised learning on huge quantity of text, by predicting words, given their context.
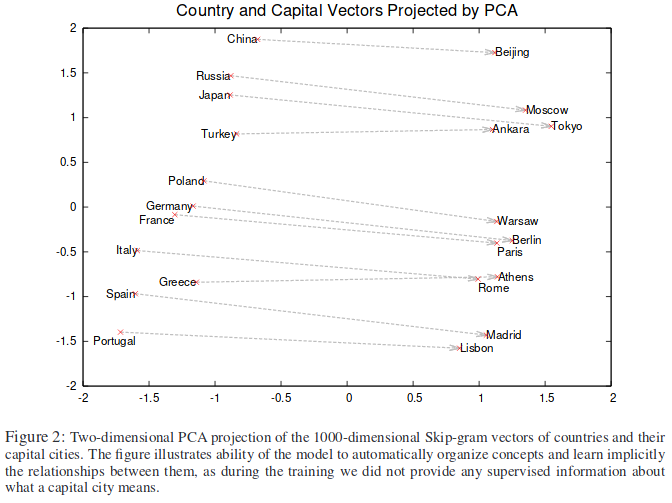
The above amazing example of word vectors having semantic relationship when performing arithmetic is actually "too good to be true" for Word2Vec, as you might not obtain the expected relationship if you compute it with the pretrained models. The original paper by the Google team in 20143 however shows the following relationships are obtained when projecting with Principal Component Analysis.
Continuous Bag-of-words
Word2vec model. Source: wildml.com
Words are one-hot vectors
Raw words are represented using one-hot encoding. That is, if your vocabulary has \(d\) words, the ith word of the vocabulary is represented by \(w\), a binary vector in \(\mathbb{R}^d\) with the ith bit activated, all other bits being off. Say "cat, dog, eat" are all words in your vocabulary. In this order, we will encode "cat" with \([1, 0, 0]\), "dog" with \([0, 1, 0]\), "eat" with \([0, 0, 1]\).
A word's context is a continuous bag of words
For representing the context of a word, Continuous Bag-of-words (or CBOW) representation is used. In this representation, each words is encoded in a continuous representation, then we take the average representation. \[ h(c_1,c_2,c_3) = \frac{1}{3}(W_i(c_1 + c_2 + c_3)) \] \(H\) computes the continous representation of context vector formed by three words \(c_1, c_2, c_3\). \(W_i\) serves in computing a word embedding for context words. From this continuous representation, we derive the target word by decoding it into a word vector \(o = W_oh(c_1, c_2, c_3)\).
We see such model can be trained in an unsupervised way, taking four consecutive words at a time, and for example using the second word as target, and the remaining three other words as context of the target word.
CBOW reversed is Skip-gram
Skip-gram reverses CBOW model, so that we try to find context words given an input word. To train such network using backpropagation, we sum the output layers, so that only one vector remains.
CBOW and Skip-gram both end up computing a hidden representation of words, given a large amount of texts. The original paper by Mikolov et al. used Skip-gram, as well as other advanced techniques, such as negative sampling, which are out of the scope of this article.
Word2vec in action
Gensim
Let's use gensim library that implements word2vec model. We download english Wikipedia corpus using the convinent gensim-data api.
from gensim.models.word2vec import Word2Vec
import gensim.downloader as api
corpus = api.load('text8') # download english Wikipedia corpus
model = Word2vec(corpus)
model.most_similar("cat")We obtain as result
[('dog', 0.8296105861663818),
('bee', 0.7931321859359741),
('panda', 0.7909268736839294),
('hamster', 0.7631657719612122),
('bird', 0.7588882446289062),
('blonde', 0.7569558620452881),
('pig', 0.7523074746131897),
('goat', 0.7510213851928711),
('ass', 0.7371785640716553),
('sheep', 0.7347163558006287)]
spaCy
spaCy is an advanced library for "industrial-strength NLP". After installing spaCy, download the pretrained model
python -m download en_core_web_lgThen
from itertools import product
import spacy
nlp = spacy.load("en_core_web_md")
tokens = nlp("dog cat banana afskfsd")
print("# Info on each token dog, cat, banana, and afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
print("# Similarity of dog, cat and banana")
for t1, t2 in product(tokens[:-1], tokens[:-1]):
print(t1.similarity(t2))